Exploring the Transformative Power of Retrieval Augmented Generation
Written on
Chapter 1: Introduction to AI and RAG
In today's era marked by rapid advancements in Artificial Intelligence (AI), we are experiencing significant changes in various dimensions of our daily lives—impacting everything from personal routines to workplace practices and communication methods.
This remarkable transformation is largely driven by innovative technologies, particularly Large Language Models (LLMs). Notable examples include GPT-3, BERT, and T5, which have gained prominence for their ability to produce coherent and relevant texts in response to user inputs.
However, it is crucial to recognize that LLMs come with inherent challenges. A primary issue is their dependence on extensive training datasets, raising concerns about the quality and representation of this data. Biases and inaccuracies may inadvertently find their way into the outputs generated by these models. Moreover, LLMs often struggle to integrate external knowledge, limiting their ability to deliver comprehensive and accurate information.
To tackle these challenges, researchers are actively working on refining LLMs. This includes enhancing the quality of training data to ensure it is diverse and representative while also enabling better access to external knowledge sources.
The Future of Artificial Intelligence - This video discusses the transformative potential of AI and its implications for various fields.
Section 1.1: Understanding the Challenges of LLMs
Delving deeper into the challenges faced by LLMs, we find that their impressive capabilities are heavily contingent upon the data they are trained on. If this training data is incomplete or outdated, the reliability of the generated texts suffers.
A significant limitation lies in LLMs' inability to effectively pull in information from external sources. While they excel at generating coherent texts, their reliance on static knowledge can lead to inaccuracies, particularly in fields where timely information is essential, such as journalism, healthcare, or legal contexts.
To address these issues, it is vital to ensure that the training datasets are not only vast but also kept up-to-date. Continuous research is needed to enhance the models' capabilities to seamlessly access and integrate external information, allowing for more precise and relevant outputs.

Photo by Google DeepMind from Pexels
Chapter 2: The Solution - Retrieval Augmented Generation
In light of the challenges discussed, Retrieval Augmented Generation (RAG) has emerged as a promising solution. This innovative method, introduced in a pivotal 2020 paper by Patrick Lewis and colleagues at Facebook AI Research, merges the generative prowess of LLMs with the ability to retrieve information from external sources.
RAG signifies a significant leap in Natural Language Processing (NLP) by effectively combining LLM strengths with the accuracy derived from up-to-date external knowledge. By tapping into diverse domains like medicine, finance, and law, RAG generates texts that are not only coherent but also enriched with precise and relevant information.
The applications of RAG are vast. For instance, in healthcare, it can utilize the latest research to produce accurate medical reports or assist in diagnosing conditions. In the legal field, RAG can reference legal databases to formulate informed opinions and advice. Similarly, financial institutions can harness RAG to analyze real-time market data for investment strategies.
The Future of Artificial Intelligence - This video explores the implications of AI advancements in various sectors and their potential impact.
Section 2.1: How RAG Operates
The operational mechanism of Retrieval Augmented Generation (RAG) can be categorized into two main phases. Initially, RAG conducts a search through external knowledge sources to identify the most relevant documents related to the input question or prompt. This phase employs advanced retrieval techniques for efficient information gathering.
Once relevant documents are obtained, RAG moves to the second phase, where it integrates this information with the original input to generate a final output. This phase capitalizes on the generative capabilities of LLMs, ensuring that the resulting text is not only coherent but also informed by the latest knowledge.
RAG's versatility is a significant asset. It can respond to various types of inputs, including questions and prompts, producing outputs such as answers, summaries, and articles. This flexibility makes RAG a valuable tool for diverse knowledge-intensive NLP tasks.
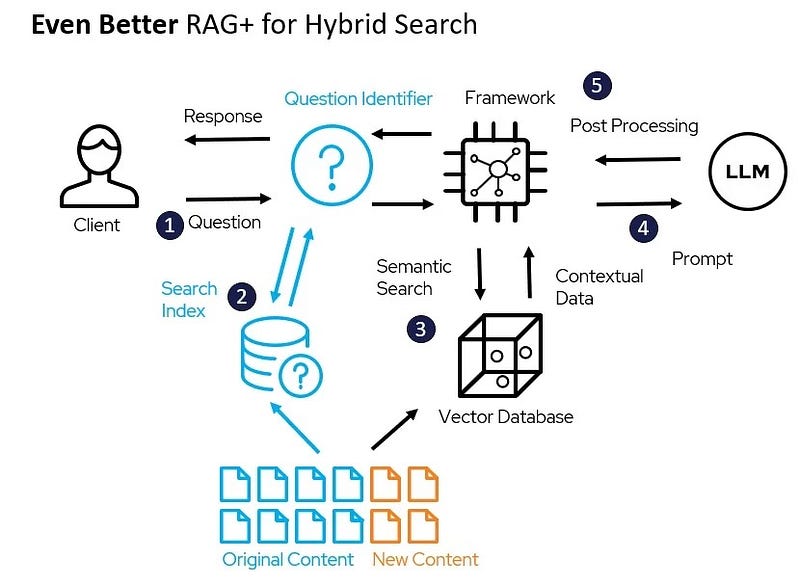
RAG+ for Hybrid Search
Chapter 3: Advantages of RAG
The implementation of Retrieval Augmented Generation (RAG) offers numerous advantages that enhance language model performance. A key benefit is its ability to improve the accuracy of responses by integrating current information from external sources, addressing limitations related to static training data.
Moreover, RAG helps mitigate common issues in language models, such as hallucinations and data loss. By validating generated content against external knowledge, RAG minimizes the chances of producing inaccurate or irrelevant information, thereby boosting the overall reliability of the outputs.
Additionally, RAG's adaptability across various tasks and domains allows it to cater to a broad range of applications. This flexibility enables RAG to perform effectively in question answering, summarization, and article generation, among other areas.

Big Data — Image produced by DALL-E3
Chapter 4: Challenges Faced by RAG
Despite its many benefits, Retrieval Augmented Generation (RAG) encounters specific challenges that must be addressed to maximize its effectiveness. The quality of retrieved data is paramount; the accuracy of generated outputs hinges on the reliability of external knowledge sources. Inaccurate or outdated information can adversely affect the quality of the results.
Additionally, RAG's dual-phase operation introduces computational and temporal complexities, requiring more resources and time than traditional language models. This can present practical difficulties, particularly for real-time applications.
Furthermore, ensuring the consistency and relevance of generated outputs is crucial. If the retrieved data does not align with the input context, the resulting text may lack coherence or relevance, underscoring the need for careful alignment between input, retrieved data, and output.
Chapter 5: Diverse Applications of RAG
The applications of Retrieval Augmented Generation (RAG) are extensive and impactful across various sectors:
- Content Generation: RAG enhances the production of original content, making it suitable for journalism, marketing, and creative writing.
- Data Analysis: By synthesizing information from multiple sources, RAG aids in data-driven decision-making and research.
- Customer Support: Companies like Meta and Oracle leverage RAG for improved customer service, providing accurate and timely information.
- Chatbots and Virtual Assistants: RAG empowers these tools to deliver informed and contextually appropriate responses, enhancing user interaction.
- Knowledge-Intensive Domains: In fields like law and medicine, RAG can supply precise and up-to-date information, supporting professionals in their work.
Final Thoughts
Retrieval Augmented Generation represents a transformative approach that merges the strengths of both retrieval and generation models. By utilizing pre-existing knowledge alongside generating new responses, RAG facilitates more accurate and informative interactions between humans and AI. This not only enhances the quality of information exchanged but also significantly improves user experiences.
As RAG continues to evolve, it promises to revolutionize human-machine interactions and pave the way for more sophisticated AI applications in the future.

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together!
